 Cassandra Clark
Cassandra ClarkIntroduction
In our increasingly interconnected world fraud has become a pervasive force. Criminals worldwide are using increasingly sophisticated techniques to steal data and money from hapless victims. These techniques cause losses of billions of dollars worldwide. Fortunately, technology is incredibly helpful for identifying these attempts at fraud.
In this article, we will focus on credit card transactions specifically. We will demonstrate how to use Enso to bring in multiple data sources to flag transactions identified by a variety of systems as fraudulent, from stolen credit card details to compromised payment terminals.
Reading Data
To start things off we’re going to read in our dataset of credit card transactions.
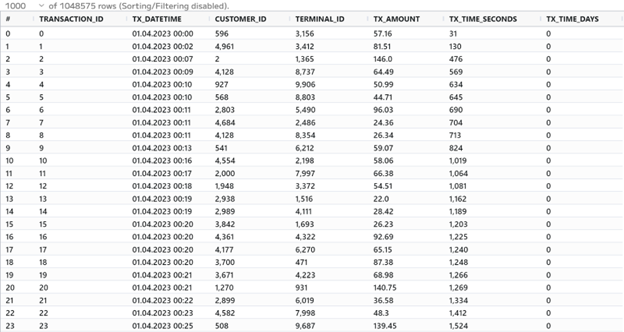
This dataset has a transaction_id which is a unique identifier per transaction, tx_datetime which shows the time the transaction occurred, customer_id which identifies each user, a terminal_id which identifies where the transaction took place, and tx_amount which is the amount of the transaction. There are two more columns, tx_time_seconds and tx_time_days, but we don’t need these for this example.

Enso automatically infers data types for you, even with text files, but in this
dataset, there are a few messy values in several fields that don’t quite conform
to the correct types, so we can use the parse function to set these
appropriately and discard any values that don’t conform.

From here, we bring in our second dataset. We use Enso’s native database support to query from our internal database directly using the same syntax as other operations. Here we can select only the three columns we need.
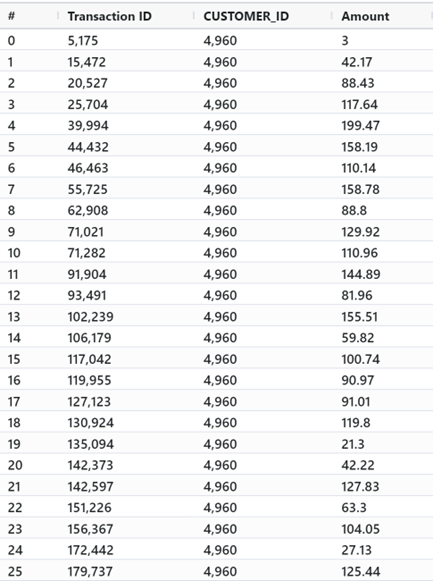
We’ll join the data where TRANSACTION_ID and CUSTOMER_ID match, and replace
any empty TX_AMOUNT values with the Amount field found in the database. We
can remove the unnecessary Transaction ID and Amount columns, as we’re done
using them.
Identify duplicates
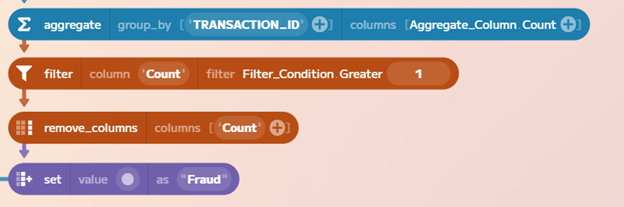
We can identify duplicate transactions in our dataset by looking for cases where
the same TRANSACTION_ID exists more than once. The aggregate method is perfect
for this. We mark these duplicates as fraudulent and bring them back into our
original dataset.
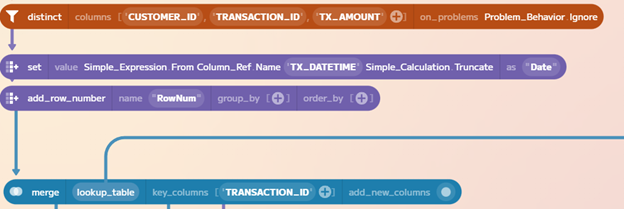
Now we’re going to add a row number so that we can apply our other fraud cases
to the test dataset. While we’re at it, we’ll also select distinct records by
CUSTOMER_ID, TRANSACTION_ID, and TX_AMOUNT, and truncate the TX_DATETIME
field to remove the time, as we don’t need that level of specificity to create
these cases.
Flagging Compromised Terminals
Next, we’re going to input a list of terminals that have been flagged as being
compromised by our system. This dataset includes only the terminal ID and the
date it was flagged. The company’s policy is to flag all transactions from a
compromised terminal for the next 28 days after the initial report. To do this,
we add an end_date field using the set method.

Let’s break this method down since it’s really powerful. Here we can select a
column operation. We get a dropdown of all of the different calculations we can
perform, and once we select one, like Date_Add, we get a dropdown listing our
columns, so we can easily select what data we want to operate on. We set our
period of 28 days, and then we set a new_name of end_date so that Enso
creates a new field.

We use Enso’s powerful join method to isolate all the transactions between two
dates, thanks to the handy Between condition. This condition will
automatically look for all dates between our start and end dates for each
specific terminal. Then we can set our Fraud column to True, and select only
the RowNum and Fraud fields as these are all that we need to update our
original dataset.

Bringing it All Together
We use the merge method to update our primary dataset. We can look up the
RowNum field, and this function will automatically update the value of our
Fraud column for any row identified as related to a fraudulent transaction on
a compromised terminal.
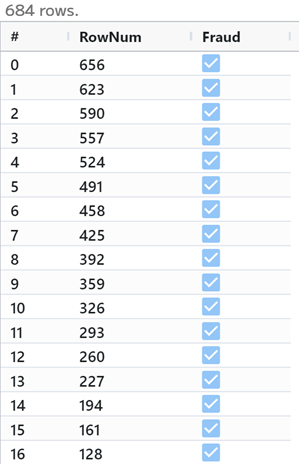

Finally, we can bring in a list of flagged customer transactions from another
dataset. This dataset CustomerFraud.csv has a lot of extra information in it,
but all we care about is marking the transactions as fraudulent, and using the
TRANSACTION_ID to update our core dataset.
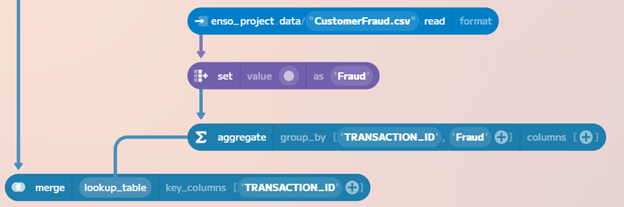
So, we set Fraud to True for these records, and then use the aggregate
method to ensure unique transactions are being selected via the Group_By
operation, and then we use lookup_and_replace once more, using TRANSACTION_ID
to mark these transactions as fraudulent.
Conclusion
We have successfully created a dataset of all of the transactions in our system for this period, with fraudulent transactions correctly identified for downstream analysis, predictive modeling, or reporting use cases.
Fraud is a major threat worldwide, and it can take a variety of shapes, but using Enso we can quickly bring together and analyze data to develop better resiliency against it.